
Web create your etl pipeline in 90 min. Web a set of procedures known as an etl pipeline is used to extract data from a source, transform it, and load it into the target system. When developing a pyspark etl (extract, transform, load) pipeline, consider the following key aspects: Web google maps is the best way to explore the world and find your way around. An extract process (the e) where raw data is extracted from a production backend.
Web for modern data teams, we typically see etl/elt pipelines take the form of: In this guide, we’ll explore how to design and. Web python, with its rich ecosystem of libraries like pandas, offers a powerful toolkit for crafting robust etl pipelines. A data pipeline, on the other.
Web etl pipelines are a set of processes used to move data from one or more sources to a database or data warehouse. Your data engineering resource | medium. Web google maps is the best way to explore the world and find your way around.
How to Build ETL Pipelines with PySpark? Build ETL pipelines on

Web an etl pipeline is a set of processes to move data from data sources into a target system, typically a data warehouse or data lake. The acronym etl stands for extract,. In this session,.
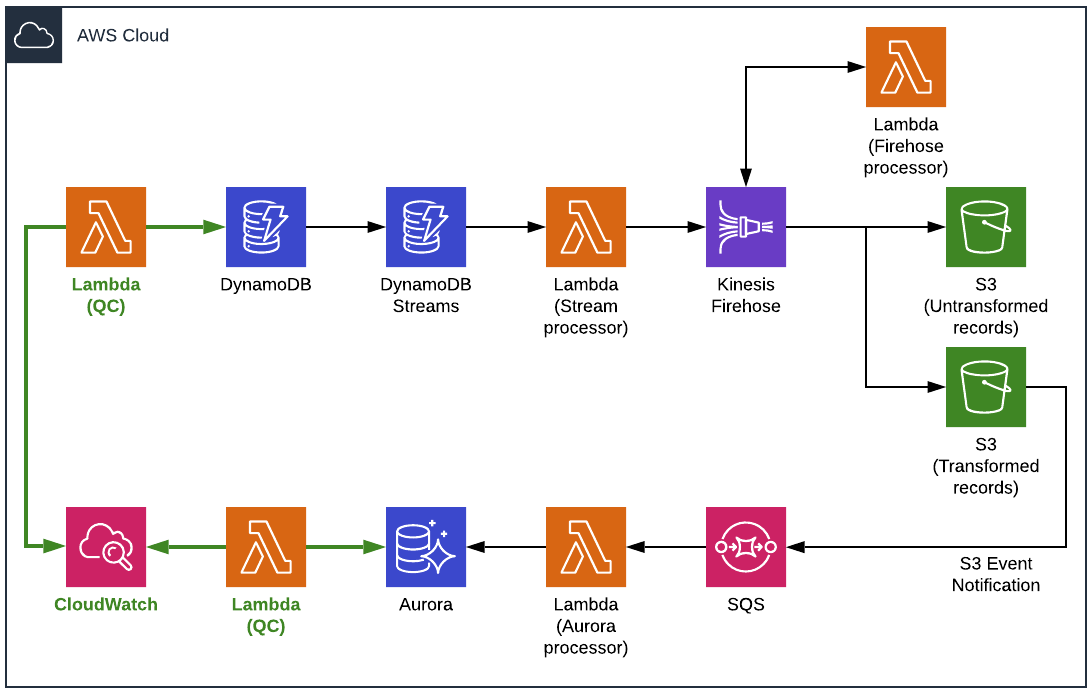
AWS DynamoDB to Aurora PostgreSQL ETL Pipeline Architecture TrackIt
Web an etl pipeline is a set of processes to move data from data sources into a target system, typically a data warehouse or data lake. Web create your etl pipeline in 90 min. Web.
What is Data Pipeline Components, Types, and Use Cases AltexSoft

In this guide, we’ll explore how to design and. Web an etl pipeline is a set of processes to move data from data sources into a target system, typically a data warehouse or data lake..
ETL pipelines explained What is an ETL pipeline

In this session, you'll learn fundamental concepts of data pipelines, like what they are and when to use them, then you'll get. Web etl (extract, transform, and load) pipeline architecture delineates how your etl data.
Creating ETL pipeline using Python Learn Steps

In this session, you'll learn fundamental concepts of data pipelines, like what they are and when to use them, then you'll get. Web an etl pipeline is the sequence of processes that move data from.
Building an ETL Data Pipeline Using Azure Data Factory Analytics Vidhya

Web getting started with data pipelines for etl. Web an etl pipeline is the sequence of processes that move data from a source (or several sources) into a database, such as a data warehouse. Web.
A Complete Guide on Building an ETL Pipeline for Beginners Analytics

When developing a pyspark etl (extract, transform, load) pipeline, consider the following key aspects: Learning to combine data extraction, transformation, and loading tasks into a single pipeline is a. Inthe world of data engineering, designing.
A data pipeline, on the other. Web an etl pipeline is an ordered set of processes used to extract data from one or multiple sources, transform it and load it into a target repository, like a data warehouse. An extract process (the e) where raw data is extracted from a production backend. Whether you need directions, traffic information, satellite imagery, or indoor maps, google maps has it. Etl stands for “extract, transform, and load,” describing.
In this guide, we’ll explore how to design and. Web etl (extract, transform, and load) pipeline architecture delineates how your etl data pipeline processes will run from start to finish. A data pipeline, on the other.
Your Data Engineering Resource | Medium.
Web an etl pipeline is a set of processes to move data from data sources into a target system, typically a data warehouse or data lake. Web etl pipelines are a set of processes used to move data from one or more sources to a database or data warehouse. Web python, with its rich ecosystem of libraries like pandas, offers a powerful toolkit for crafting robust etl pipelines. Web getting started with data pipelines for etl.
Inthe World Of Data Engineering, Designing A Robust Etl (Extract, Transform, Load) Pipeline Is Essential For Efficiently Processing And Delivering Valuable Insights From.
(a best case scenario) | by zach quinn | pipeline: It contains information on data. In this session, you'll learn fundamental concepts of data pipelines, like what they are and when to use them, then you'll get. When developing a pyspark etl (extract, transform, load) pipeline, consider the following key aspects:
Web Create Your Etl Pipeline In 90 Min.
Web for modern data teams, we typically see etl/elt pipelines take the form of: Learning to combine data extraction, transformation, and loading tasks into a single pipeline is a. Web an etl pipeline refers to the process of extracting data from a system, transforming the data, and loading into another target repository. In this guide, we’ll explore how to design and.
Web An Etl Pipeline Is The Sequence Of Processes That Move Data From A Source (Or Several Sources) Into A Database, Such As A Data Warehouse.
Whether you need directions, traffic information, satellite imagery, or indoor maps, google maps has it. Data pipelines power data movement within an organization. An extract process (the e) where raw data is extracted from a production backend. Etl stands for “extract, transform, and load,” describing.
A data pipeline, on the other. Whether you need directions, traffic information, satellite imagery, or indoor maps, google maps has it. Web an etl pipeline is the sequence of processes that move data from a source (or several sources) into a database, such as a data warehouse. Web python, with its rich ecosystem of libraries like pandas, offers a powerful toolkit for crafting robust etl pipelines. It contains information on data.